
Si hay algo que define la web, es que es una telaraña de mentiras, desinformación y propaganda. Casi cualquier dato o hecho interesante está a nuestro alcance, pero separar el grano de la paja es a menudo imposible.
¿Y si hubiese una forma de distinguir automáticamente, mediante un algoritmo, los hechos de la ficción? Según Joseph Stevanak y Lincoln Carr, de la Escuela de Minas de Golden (Colorado), ese algoritmo existe, al menos hasta cierto punto. Según un estudio de ambos investigadores, el análisis matemático de la red semántica de un texto permite determinar con extraordinaria precisión si estamos tratando con una obra de ficción o una noticia periodística.
Para un ser humano, normalmente no es difícil distinguir entre novelas, ensayos, noticias y otros géneros literarios. Por un lado, nos basamos en claves contextuales, como la presencia de titulares, entradillas, etc. Además, el texto en sí ofrece muchas pistas; por ejemplo, las noticias suelen responder a un formato rígido y estructurado que limita en gran medida la creatividad del autor. Pero lo que resulta obvio para una persona no lo es tanto para un programa de ordenador.
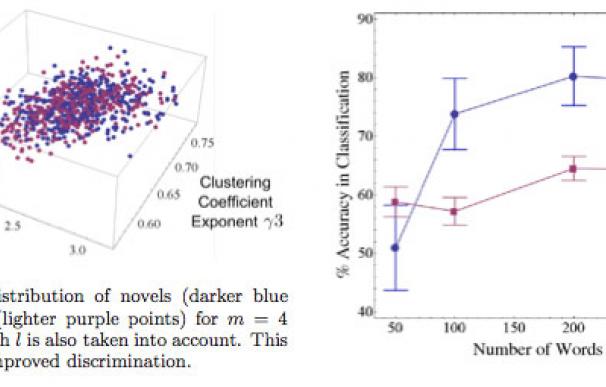
La clave del método ahora propuesto consiste en utilizar la teoría de redes complejas para analizar las redes semánticas que se forman al registrar la frecuencia de aparición de palabras adyacentes.
Para ello, se crea un grafo en el que cada palabra es un vértice, conectándose mediante una arista las palabras que aparecen juntas en el texto (o, si se desea, a dos palabras de distancia, tres, o más). Una vez creado el grafo, los investigadores únicamente deben analizar dos propiedades del mismo: la ley de potencias, que describe el número de enlaces de cada vértice, y el coeficiente de agrupamiento, que indica cuán bien se conecta cada vértice con el resto del grafo.
Usando apenas esos dos parámetros es posible detectar los textos de ficción con una precisión del 73,8%, y las noticias con un 69,1%.
Aunque ciertamente hoy por hoy no va a substituir a Google, este tipo de análisis tiene aplicaciones inmediatas, al permitir afinar las búsquedas para ofrecer al usuario resultados más acordes con sus intereses. Y, francamente, a la hora de explorar la web, cualquier ayuda es bienvenida.
Hemos bloqueado los comentarios de este contenido. Sólo se mostrarán los mensajes moderados hasta ahora, pero no se podrán redactar nuevos comentarios.
Consulta los casos en los que lainformacion.com restringirá la posibilidad de dejar comentarios